Utility Theory (Beta)
簡介
機器人SDK的效用理論仍然在搶鮮版版本,這意味著目前還在為生產做準備,並且API及效能將在未來的版本中改善。
概述
效用理論AI工作的方式是提供一個架構來用於決策,這個決策強烈地基於數學模型。當建立您自己的UT代理時,您將持續地建立及調整回應曲線,其使用Unity的動畫曲線來作為自己的定義。
每個回應曲線收到一個由您自己的遊戲邏輯來定義的輸入值,而且其輸出是我們在這裡稱為分數。在這個流程之後,UT代理將知道哪些是在該刷新時 更有用的 可能的選項(因此,稱為 效用 理論),並且將據此開始行動。
比較之下,效用理論與有限狀態機及行為樹有很大的不同,並且當談到AI技術在多大程度上能建立沉浸式行為時,效用理論更類似於目標導向動作計劃,因為它並不強制使用者在所有事情之間建立一個非常「固定」的關係,比如FSM的轉換及BT的連結。
UT AI的其中一個最大的優勢是,有了回應曲線,就可以定義一個非常彈性的決策空間。舉例而言:
- 假設HFSM的決策中的距離檢查:如果代理與敵人的距離小於5,則代理應該逃跑。這會建立一個「隱形的牆」,也就是一個「二進位閾值」,其中決策從一個極端走向另一個極端(從「不要逃跑」到「要逃跑」);
- 有了UT的回應曲線,可以透過曲線本身的主體來讓決策變得平滑。它可以是一條線性曲線,其中最大效用值為5。這意味著,隨著距離值接近5,逃跑成為 線性上更重要 的選項。或者,它可以是指數增長的曲線,這讓逃跑的決策變得更有用,甚至更快。
建立一個新的效用理論AI
在編輯器的頂端列,按一下(+)按鈕,然後選擇效用理論選項。

注意事項:您現在選擇的名稱,將是在您編譯您在視覺編輯器上已經完成的工作時進一步生成的另一個資料資產的名稱。
這將是用於從Quantum模擬來實際驅動您的機器人的資料資產,所以您已經可以選擇一個有暗示性的意義的名稱。
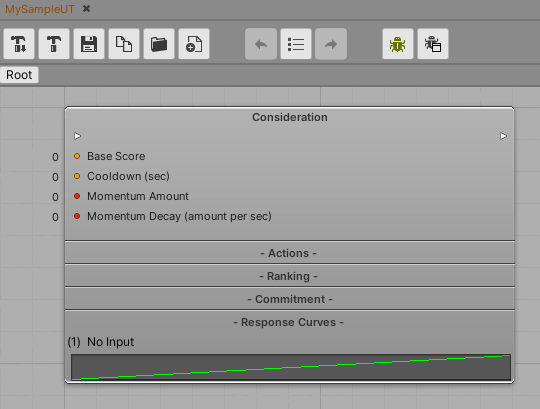
當您儲存檔案,主要機器人SDK視窗將被一個單一節點填入,其為 考量節點,來讓您開始您的工作。
考量節點
這是主要節點類型,其含有所有對於UT代理而言重要的資料。
在考量範圍內,可以定義特定考量所分析的回應曲線。之後這些曲線將由0到n的分數值所得出,這些分數值將相乘,得出的結果就是我們所稱的「執行該考量的效用」。
首先,評估所有考量,這意味著將輸入放入曲線中,以獲得結果分數。然後,選擇得分最高的考量,作為在該特定幀中執行的考量。
所以我們的想法是,使用者將建立許多考量節點,其將被頻繁地評估,它們的執行將驅動代理採取行動。
讓我們來分析考量的欄位,一個一個的分析。

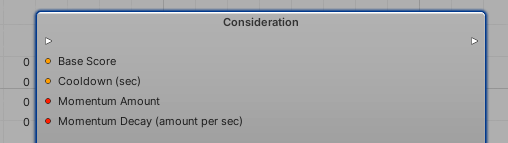
基本分數(FP): 回應曲線的結果由基本分數來加總。使用這個來為一個給定考量提供一些固定效用值;
冷卻(FP): 當選擇及執行考量,冷卻定義了從可能的選項中放棄考量的秒數;
動量數量(Int): 如果選擇了考量,動量將增加其排名到這個欄位定義的值。這樣將增加它們的絕對效用值,因此使用它以定義哪個考量可能應該持續在更多幀上被執行。請參見下述的排名主題以取得更多資訊;
動量衰退(Int): 如果考量是在動量中(換句話說,它的排名因為動量而增加),它的排名值將在每一秒根據這個欄位定義的數量而減少。使用它來表達您希望動量完成的速度;
這些基本值並不是強制使用的,但是它們確實提供一些額外的功能性,這些功能性可能非常有用。
動作
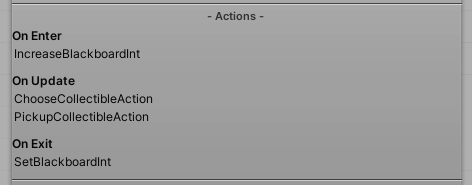
這是一個節點類型,其允許使用者來執行遊戲狀態的更改,以驅動它們的動作項目。從A點到B點移動一個動作項目,攻擊,掃描等等,可以全部在動作中完成。
UT的動作與用於HFSM上的及GOAP上的相同。因為這樣,您可以存取一個共享的文檔,存取文檔請按一下這裡。
為了編輯一個考量的動作,只需按兩下動作區域。在那之中,在下列時刻您將能夠連接動作:
- 進入時:當該考量被選擇為最有用且開始執行時執行;
- 更新時:在每個幀時,同時考量仍然被選擇為最有用時執行;
- 離開時:當考量在前一幀被選擇,但在目前幀沒有再次被選擇時執行;
排名

有兩個主要的選擇考量的方式。這裡被定義為:
- 絕對效用:排名值最高的考量比起排名值較低的考量而言有絕對優先順序,這意味著較低的在計算分數時將完全被忽略;
- 相對效用:這個是已經解釋過的,其就是分數本身,從回應曲線來評估。
排名值以整數形式來計算。舉例而言:假設有5個考量(A、B、C、D及E)。讓我們假設它們的排名值:
- A = 0;
- B = 1;
- C = 1;
- D = 2;
- E = 2。
這意味著,在該幀,D及E考量有著絕對優先順序,並且將對它們的回應曲線進行評估及比較,以在它們之間進行選擇。A、B及C考量將被忽略。
更改排名值有兩種主要方法,並且總是在運行階段定義,而且在每個幀可以更改。這個動態排名值很有用,這樣使用者可以預先定義一些針對它們的遊戲的排名邏輯,根據需要來提供優先順序給一個考量的子集。
舉例而言:讓我們假設一個遊戲,其中一個射手可以參與戰鬥,或是跑去治療。對於各個類型的可能性,可能有許多考量。為了在某些時刻篩選更為重要的考量,增加排名值以向UT代理表達這一點,可能很有用。
只有兩個方法來定義排名值:
定義您自己的排名邏輯:從Quantum解決方案,可以繼承於AIFunctionInt層級,以執行一些傳回一個整數值的邏輯,這裡是一個程式碼片段:
C#
namespace Quantum
{
[System.Serializable]
public unsafe class SampleRank : AIFunctionInt
{
public override int Execute(Frame frame, EntityRef entity = default)
{
// Add here any logic to calculate the desired Rank
return 0;
}
}
}
舉例而言,可以有一個IsDangerRank,其讀取遊戲狀態/黑板值,以識別代理是否目前有危險,這意味著有一些敵人靠近它,或有LoS接近它。如果偵測到危險,增加傳回一個10的排名值,這意味著有著該排名的考量現在將有一個非常高的絕對優先順序。如果沒有危險,則傳回0。
當編譯了您的Quantum程式碼,內容選單中就會出現功能節點。為了存取排名節點,按兩下在考量節點上的排名區域。
也可以基於動量的概念來更改排名值,將在下述的主題中說明。
動量
透過使用來自一個考量的基本值,可以指定動量,其被選取時,自動增加一個考量的排名(類似於進入時邏輯)。
擁有動量的目的是防止代理過於頻繁地改變主意。因為持續重新評估考量,它可能導致一個代理開始進行一些工作(比如追逐一個目標)並且過快切換到另一個工作(比如回到保護基地),這樣代理可能什麼也沒完成。
有了動量,您可以接著指定考量的排名增加,其建立(我們稱為) 一個承諾 到選取的工作。動量生成的排名值比起動態地計算的排名值有 更高的優先順序。
現在我們建立了一些動量,什麼時候它會再次被重新設定?有兩個主要的方式將它減少回零:
- 透過使用稱為
Momentum Decay的基本值,可以指定一個值,其將用於減少動量的排名,一秒一秒減少。所以取決於您設定動量值的方式,它可以只耗用承諾的一秒,或許多秒。這取決於您的決定; - 也可以透過 承諾 檢查器類型,來取消動量的排名,檢查器類型將傳回一個布林值,您可以用其來指定動量應該被取消 的時間。為了建立承諾檢查器,繼承於
AIFuncionBool並且執行其Execute方法。當傳回值FALSE,這意味著動量應該被取消。
C#
namespace Quantum
{
[System.Serializable]
public unsafe class SampleCommitment : AIFuncionBool
{
public override bool Execute(Frame frame, EntityRef entity = default)
{
// Implement your checking logic here
return false;
}
}
}
當編譯完您的Quantum程式碼,功能節點將在內容選單上可用。為了存取承諾節點,按兩下承諾區域。
想法是您可能希望 在許多時間內保持一個高排名值,直到完成某些條件。舉例而言,如果您有一個代理,其跟隨另一個角色,當角色開始跟隨,您可能希望它有一個大的排名值,這時設定動量衰退的值為零,所以它保持高,並且新增一個承諾,其檢查代理是否仍然真的可以到達它的目標(這可以是個簡單的距離檢查)。如果目標真的太遠,傳回False將再次將考量的排名歸零,從而增加其他事物對代理更有用的可能性。
也就是說,不強制使用這些技術,也不強制排他地使用。您可以新增動量到考量之中,並且有一個自然動量衰退 及 一個承諾檢查器。一切都取決於您的需要。
回應曲線

這是這個AI技術的核心。所有決策是基於定義曲線、得分、它們相乘及結果的組合,以取得針對該幀而言更有用的決策。
我們正在重新使用Unity的AnimationCurve系統,以定義曲線,其之後被編譯到其確定性版本之中,這個版本稱為FPAnimationCurve。
當建立您自己的曲線時,這裡最重要的是,使用正確地表達您希望考量被評估的方式的曲線。是否只有在非常接近某個特定值時,某些行為才重要?重要性是否呈線性增長?或者可能是呈指數增長?它可能在特定範圍內為零,然後在某個點之後開始線性增長?
建立您自己的曲線,選擇預設設定之一並且建立新的預設設定。
一個需要記住的非常重要的概念 是,曲線的Y軸(其是結果分數)應該被標準化(也就是在0到1之間)。這非常重要,因為曲線的結果被相乘,所以需要維持比例,不然曲線的結果將不是真的可以互相比較的,這樣就破壞了UT的原則。
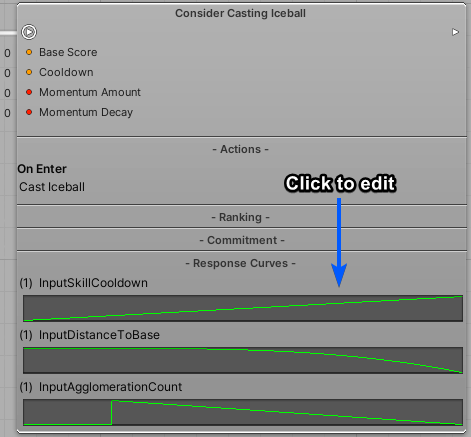
這裡是一些儲存為預設設定的,並且用於「施法者」範例的回應曲線的範例圖案:
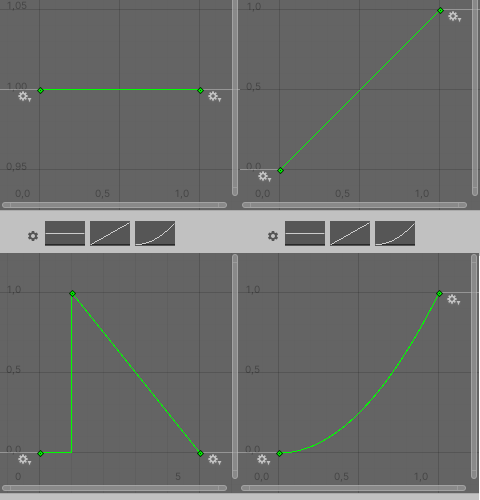
為了針對一個考量來定義更多回應曲線,按兩下曲線區域。它將帶您到曲線容器。
使用滑鼠右鍵以建立一個新的回應曲線。
按一下曲線以開啟它的編輯器視窗。
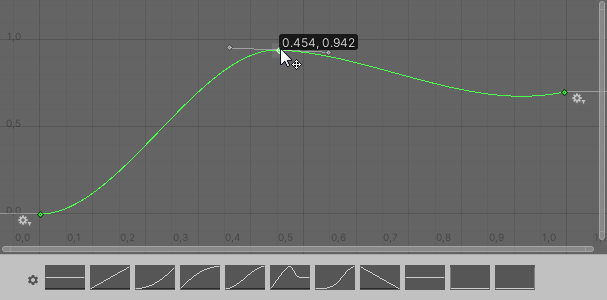
使用哪個曲線的決策完全取決於您的遊戲特定需要。它取決於 在該曲線上將插入哪個輸入,以及您希望該輸入值的該改變如何反映在一個「效用」值上。
舉例而言:
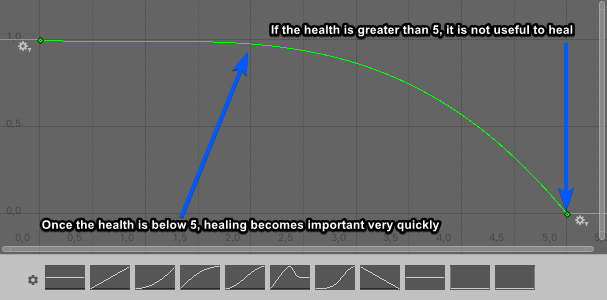
考量治療:假設一個代理具有10的最大生命值,並且在生命值低於5的時候開始期待治療。這樣,對於大於5的值,效用曲線的結果應該為零。然後,對於低於零的值,我們希望治療的效用增加的非常快。這個可能是一條正確地表達這個需要的曲線:
考量攻擊:假設一個代理只有在場景中至少有一個敵人時才希望攻擊。不管是有一個、兩個或十個敵人都一樣。這是一個「二進位閾值」曲線,其中它從零立刻到一。儘管它移除了我們在使用曲線時擁有的一些表現可能性,它仍然可以用於某些分析類型。曲線將看起來如此:
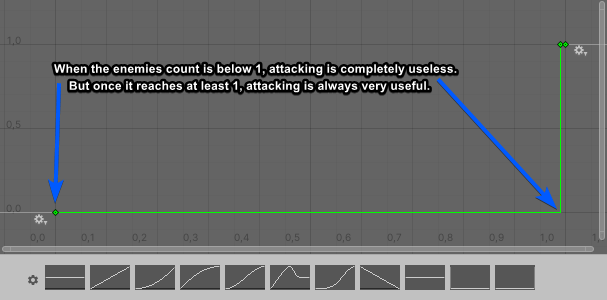
然後,一個考量將有超過一個回應曲線,是正常的(但不是強制性的)。只要根據您的需要持續建立新的曲線就行。同時需要關注為了讀取用於曲線上的輸入,而新增的額外負荷(下個主題中有關於這個的更多細節)。
可以從根檢視來看見並且編輯回應曲線:
針對回應曲線的輸入
輸入值由自訂使用者邏輯來定義,因為這是非常特定於遊戲的。它可以是來自一個實體的元件的一個生命值,它可以是儲存在黑板的一些資料,它可以是從某些感應器系統收集的事情等等。
為了建立您自己的輸入類型,建立一個新的層級,其繼承於AIFunctionFP,並且執行其Execute方法。
C#
using Photon.Deterministic;
namespace Quantum
{
[System.Serializable]
public unsafe partial class InputEntityHealth : AIFunctionFP
{
public override FP Execute(Frame frame, EntityRef entity = default)
{
// Read the current health from the component which is in the Agent's entity
if(frame.TryGet<Health>(entity, out var health) == true)
{
return health.Current;
}
else
{
return 0;
}
}
}
}
當您的Quantum程式碼被編譯,功能節點將在內容選單上可用。為了存取回應曲線節點,在考量節點上按兩下回應曲線區域。
已連接考量
可以連接一個考量和其他考量,建立一個上層下層關係。
在這個情況下,只有在特定的幀,上層考量被選為最有用時,才會評估下層考量。當它發生時,下層考量只會與它們的同層考量競爭。
這主要有兩個有用的理由:
- 它有助於效能最佳化。想像一下,上層考量分析「戰鬥是否有用」,而下層考量實際上評估做出何種戰鬥選項。直到戰鬥是有用時,才計算戰鬥選項;
- 對於效能問題,上層考量中含有的曲線並不是隱含地針對所有其下層而計算的,因此不需要重新計算這些曲線已重複次數;
- 它有助於以「內容的」方式來組織考量,其中上層考量的曲線不需要被複製到它的下層之中;
為了連接考量,簡單地按一下考量節點上的輸出槽,並且連接它到其他考量節點的輸入槽:
編譯您的效用理論AI
為了實際上使用您所建立的UT,您必須編譯您的工作。
為了編譯,您有兩個選項:

- 左按鈕只用於編譯目前開啟的文件;
- 右按鈕用於編譯您在您的專案上有的每個AI文件。
您的UT檔案將位於:"Assets/Resources/DB/CircuitExport/UT_Assets"。

設定AI以讓您的機器人使用
為了最終使用建立的AI,您只需要參照已編譯資產。
您可以基於GUID來載入資產以完成這件事,或您只需要建立一個AssetRefUTRoot以指向所需的AI資產:
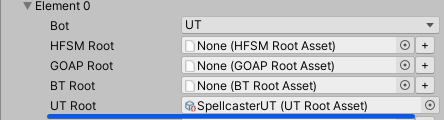
效用理由器
效用理由器是在Quantum側的主要架構,負責所有UT架構。它持有針對得分及選擇考量的所有相關資料。
如果您希望理由器被綁定到一個特定的實體,以被您的代理考量,那麼您可以新增一個名為UTAgent的元件到該實體。它 可以透過Quantum程式碼或直接在實體原型上來完成。 UT代理已含有一個效用理由器。
直接在原型上完成它的優勢是,它讓直接從Unity參照UTRoot資產成為可能,這可能相當實用。
理由器是一個常規Quantum架構。它由稱為UTAgent的元件使用,這在下一個主題中將說明,但是理由器也可以作為DSL上的global資料的一部分來被宣告。整個UT API有EntityRef entity參數作為可選的選項。所有這些意味著可以建立一個(或更多)理由器,其完全不綁定到一個實體,針對更為抽象的概念時,比如在一個即時戰略遊戲中的「虛擬玩家」,其決定在哪裡/何時/如何繁衍生物時,這可以很有用。
為了使用作為全域資料的一部分的理由器,簡單地宣告及參照它如下:
// In any DSL file
global
{
UtilityReasoner UtilityReasoner;
}
// In any other logic file, such as inside a System
f.Global->UtilityReasoner
初始化及更新
這是初始化一個效用理由器的程式碼片段,以使用UT代理元件為例:
C#
UTManager.Init(f, &utAgent->UtilityReasoner, utAgent->UtilityReasoner.UTRoot, entity);
這是針對更新一個效用理由器:
C#
UTManager.Update(f, &utAgent->UtilityReasoner, entity);
定義欄位值
關於設定值到考量、輸入、排名及承諾上的欄位,如需取得更多替代方案的資訊,請參見:定義欄位值。
AI參數
如果您希望有更彈性的欄位,其可以透過不同的方式定義:如手動設定或從黑板/常數/設定節點來設定,可參見更多關於如何使用AIParam類型的資訊,請參見:AI參數。
AI內容
關於如何傳送代理內容資訊作為參數,如需取得更多資訊,請參見:AI內容。
機器人SDK系統
有一個層級用於自動化一些流程,比如解除配置黑板記憶體。如需取得更多關於它的資訊,請參見:機器人SDK系統。
視覺編輯器註解
如需取得更多關於如何在視覺編輯器上建立註解的資訊,請參見:視覺編輯器註解。
更改編譯匯出資料夾
預設下,機器人SDK的編譯生成的資產將被放在Assets/Resources/DB/CircuitExport資料夾之中。如需取得更多關於如何更改匯出資料夾的資訊,請參見:更改編譯匯出資料夾。
選擇已儲存歷史大小
可以更改儲存在機器人SDK檔案上的歷史輸入條目的數量。如需取得更多關於這個主題的資訊,請參見:更改歷史儲存計數。
Back to top